手眼标定的问题
This tutorial aims to describe the problem that the hand-eye calibration solves as well as to introduce robot poses and coordinate systems that are required for the hand-eye calibration. If you are not familiar with (robot) poses and coordinate systems, check out 位置、方向和坐标变换.
机器人如何拾取物体?
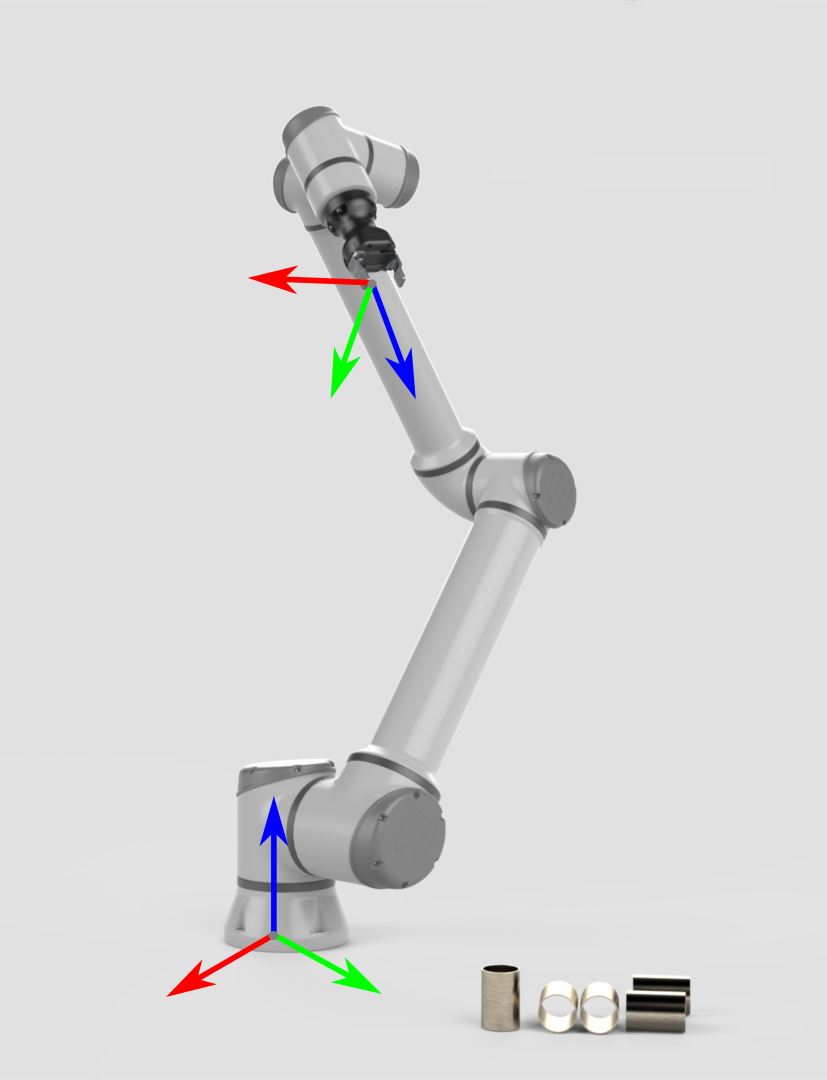
让我们从一个不涉及到相机的机器人开始。它的两个主要坐标系是:
|
|
To be able to pick an object, the robot controller needs to know the object's pose (position and orientation) relative to the robot base frame. It also requires knowledge about the robot's geometry. This combined information is sufficient to compute the joint angles that will move the end-effector/gripper towards the object. |
|
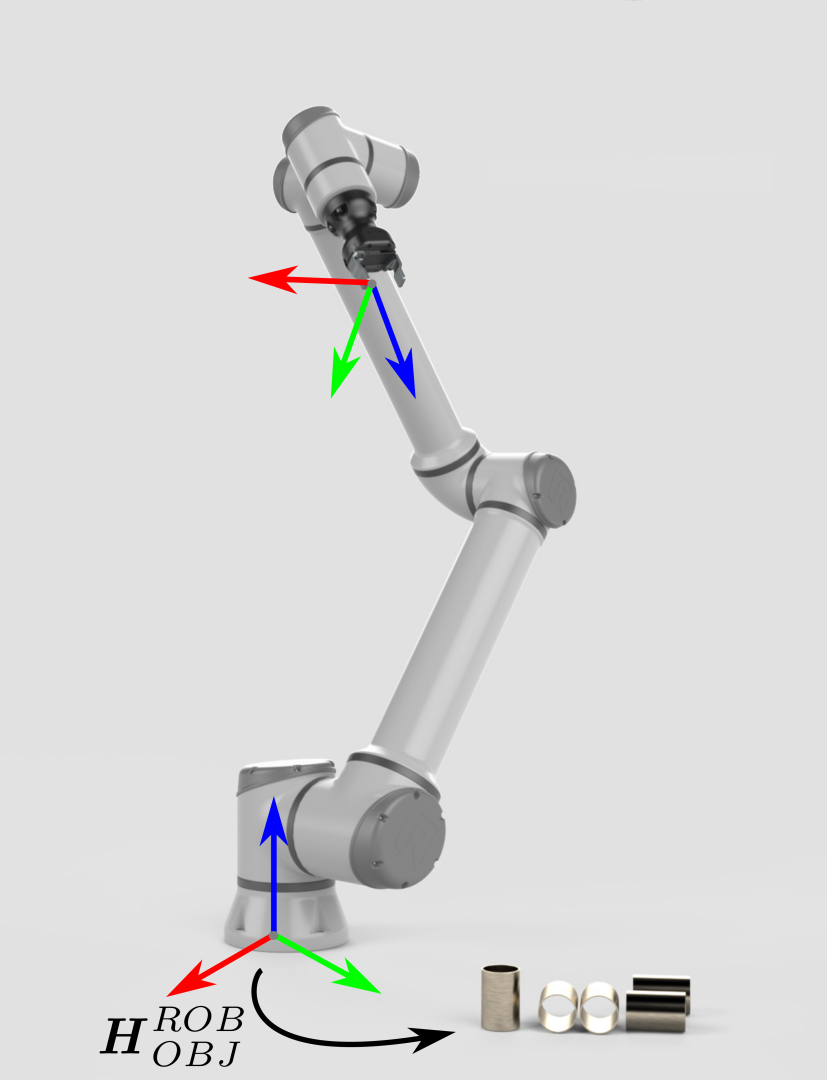
假如物体相对于机器人的位姿是未知的,那么这就是Zivid 3D视觉发挥作用的地方了。 |
|
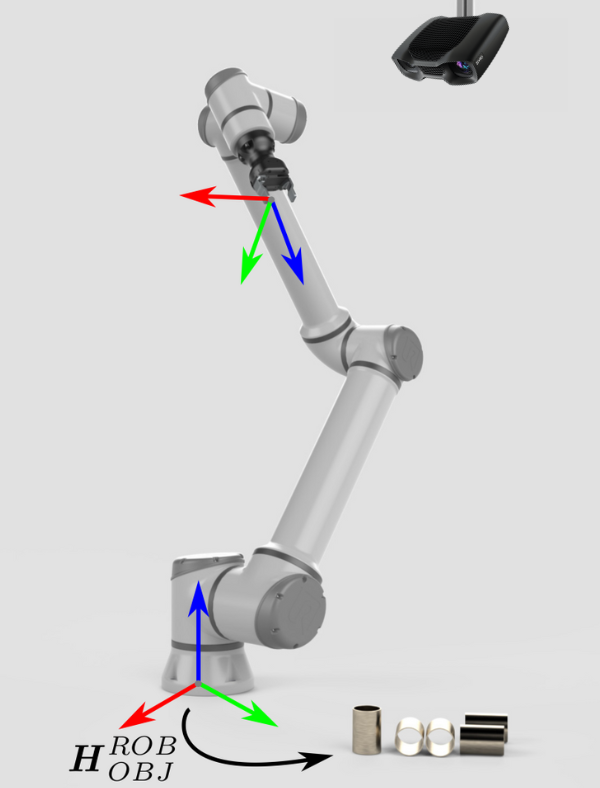
假如物体相对于机器人的位姿是未知的,那么这就是Zivid 3D视觉发挥作用的地方了。 |
|
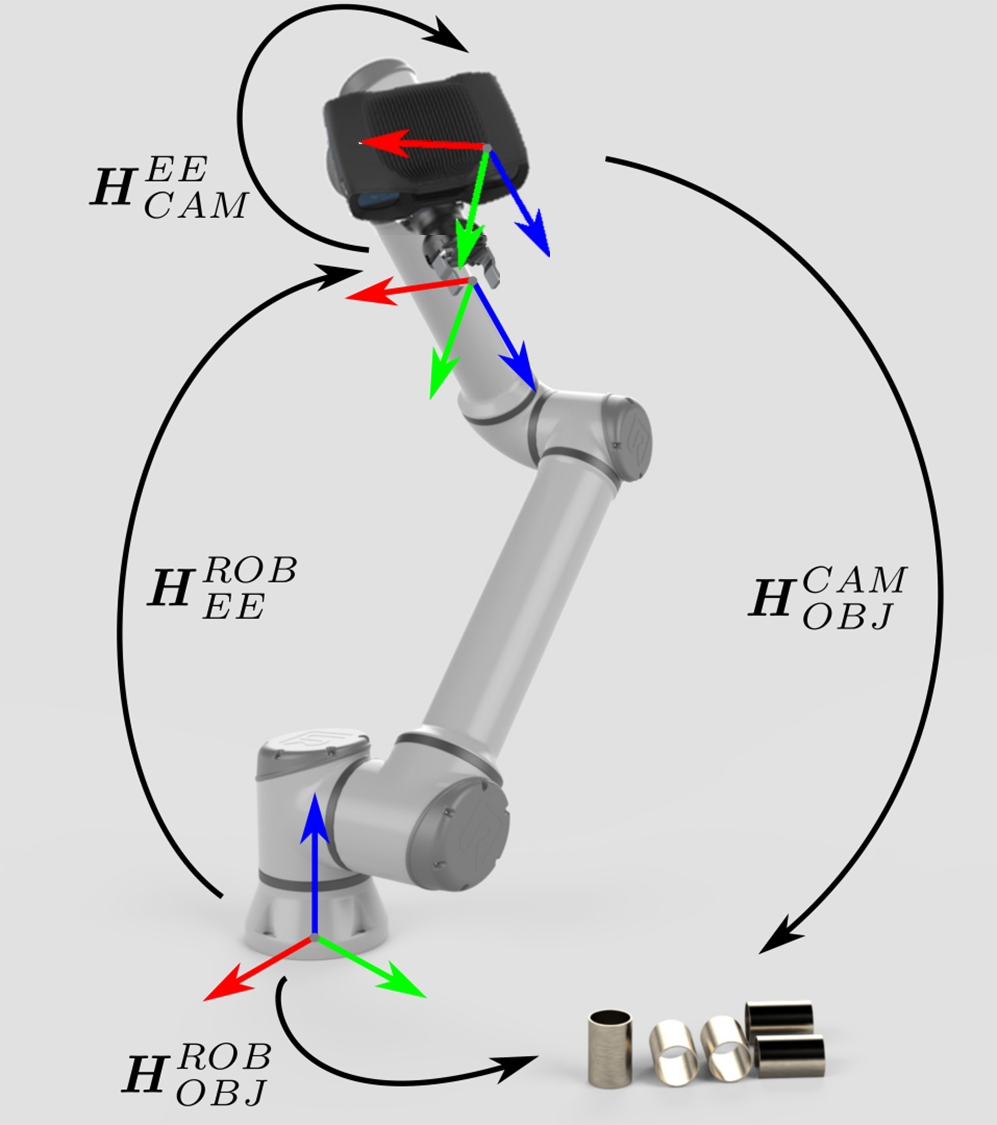
Zivid相机输出的点云是基于相机坐标系的。该坐标系的原点在Zivid成像器镜头(内部2D相机)的中间。机器视觉软件可以在此数据点集合上运行检测和定位算法,确定物体在Zivid相机坐标系中的位姿 (\(H^{CAM}_{OBJ}\))。
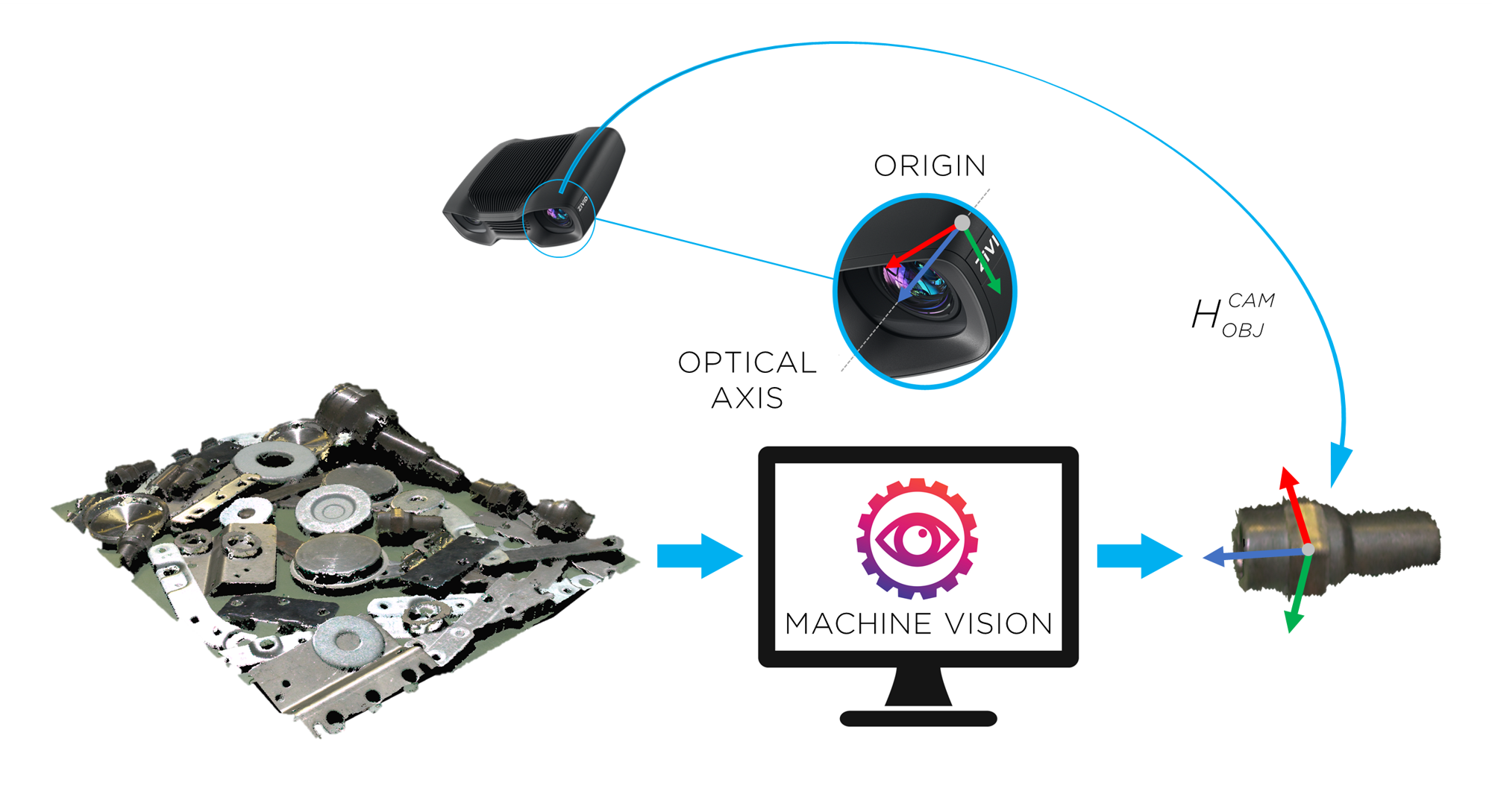
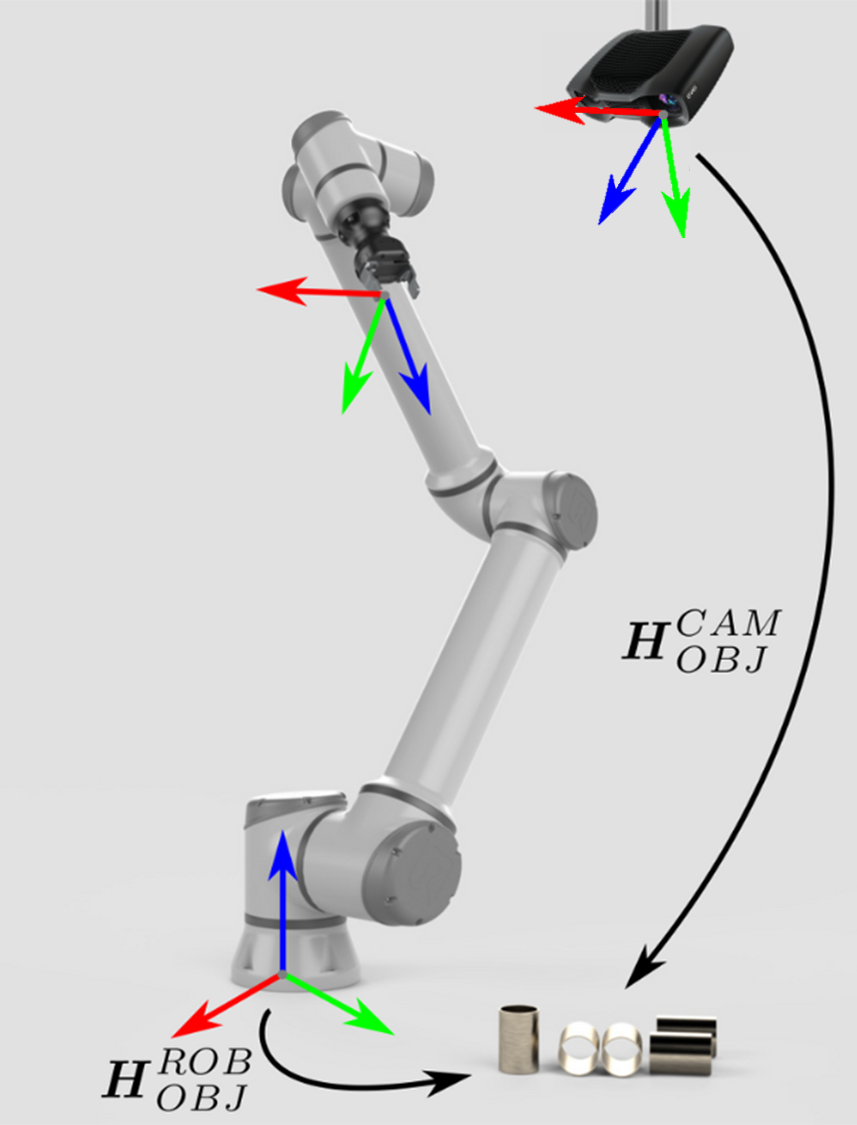
Zivid camera can now see the object in its field of view, but relative to its own coordinate system. To enable the robot to pick the object it is necessary to transform the object's coordinates from the camera coordinate system to the robot base coordinate system. |
|
The coordinate transformation that enables this is:
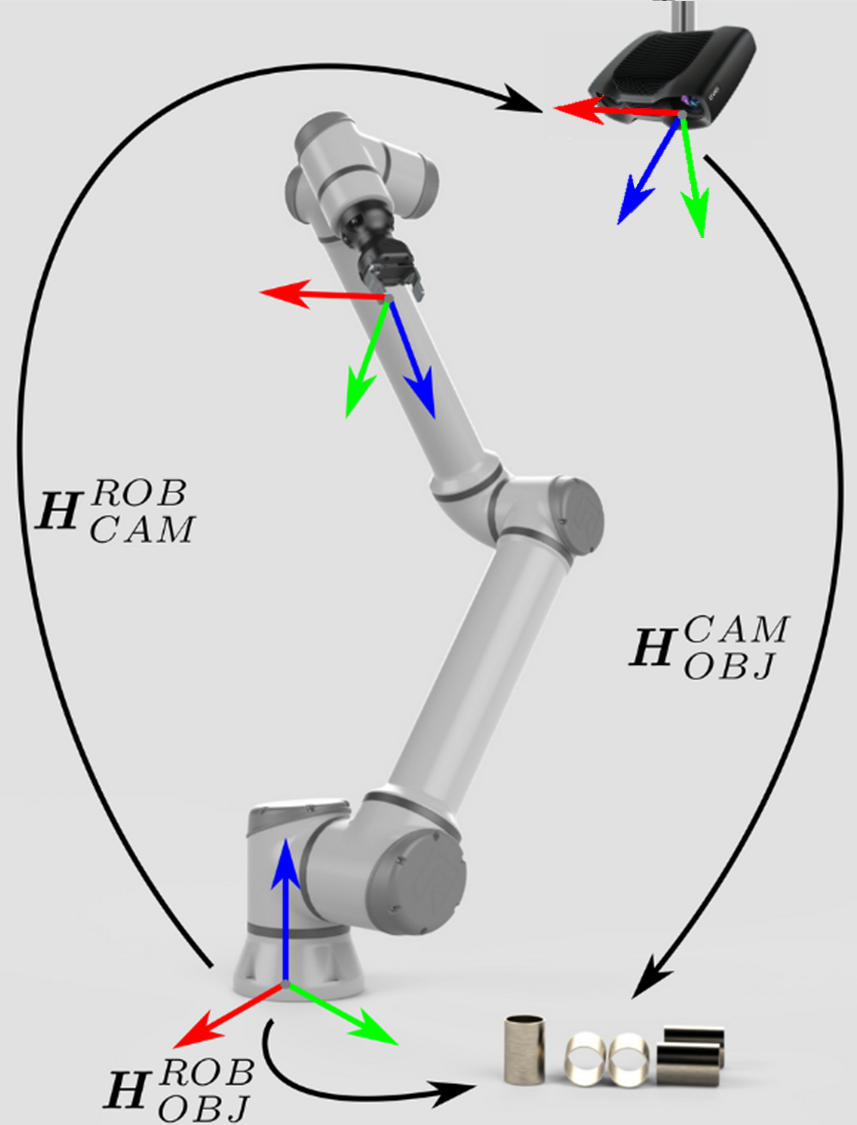
This transformation is constant and the result of hand-eye calibration. 位姿关联完成后,就可以通过关联圈中的任意一种位姿数据计算出另一位姿。在这里,物体相对于机器人的位姿,是通过将相机相对于机器人的位姿与物体相对于相机的位姿通过后乘法得到的:
\[H^{ROB}_{OBJ}=H^{ROB}_{CAM} \cdot H^{CAM}_{OBJ}\]
|
|
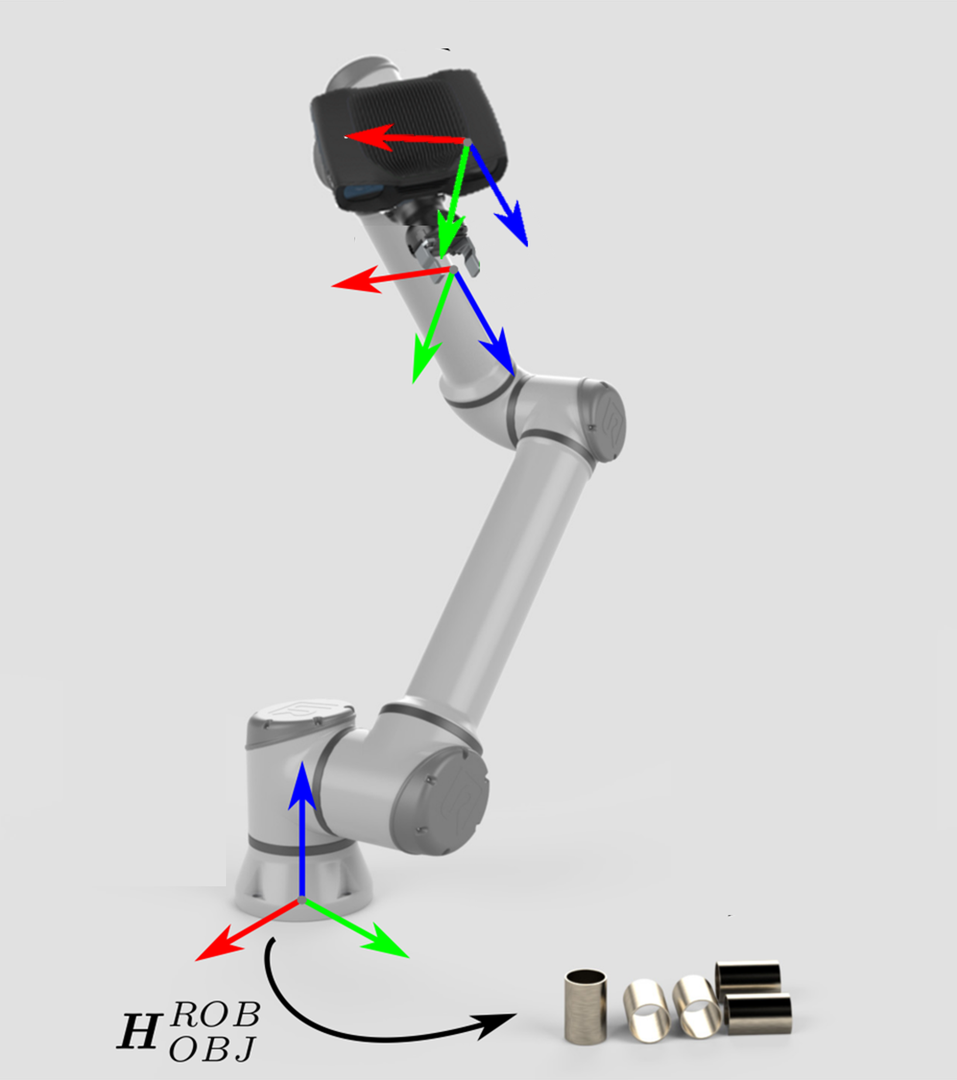
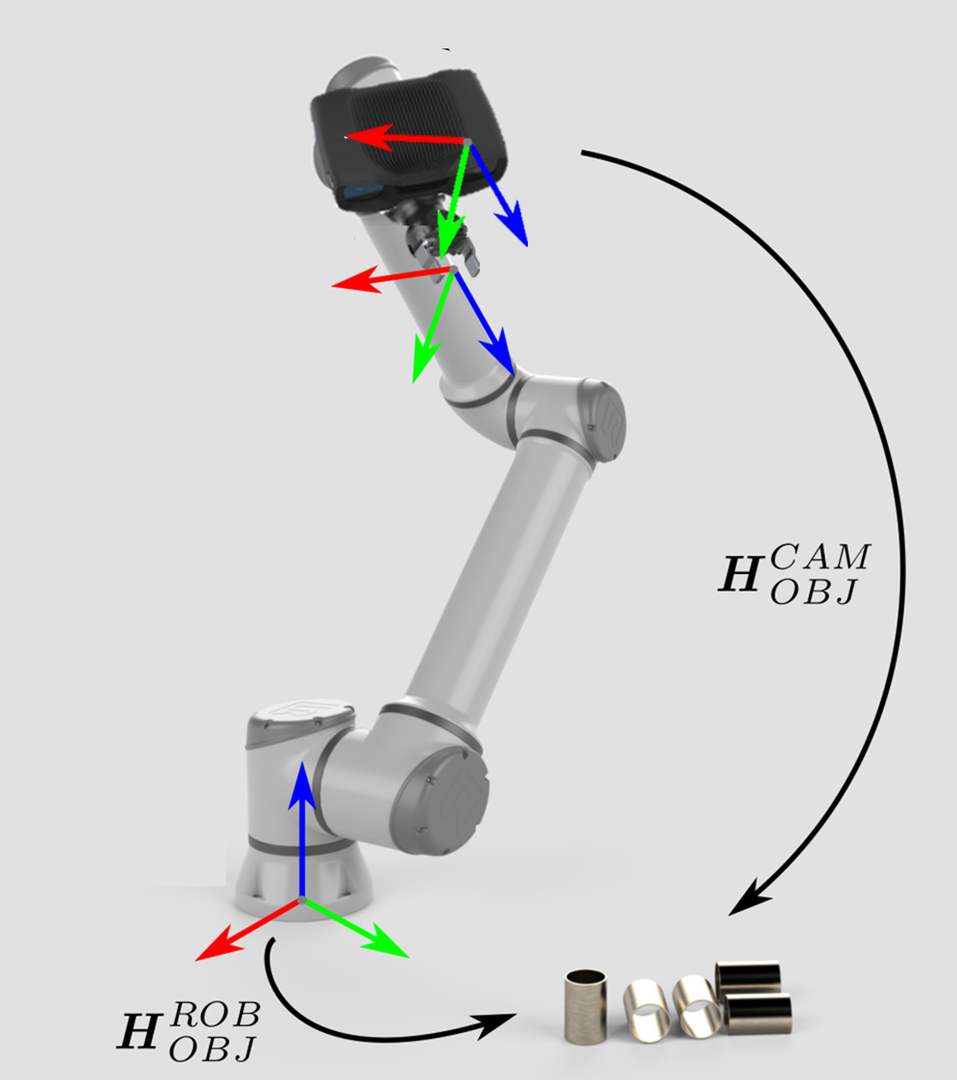
Zivid camera can now see the object in its field of view, but relative to its own coordinate system. To enable the robot to pick the object it is necessary to transform the object's coordinates from the camera coordinate system to the robot base coordinate system. |
|
The coordinate transformations that enable this are:
The former is constant and the result of hand-eye calibration, while the latter known and provided by the robot controller. Once the pose circle is closed, it is possible to calculate one pose from the other poses in the circle. In this case, the pose of the object relative to the robot:
\[H^{ROB}_{OBJ}=H^{ROB}_{EE} \cdot H^{EE}_{CAM} \cdot H^{CAM}_{OBJ}\]
|
|
现在我们已经定义了手眼标定的问题,让我们看看 手眼标定解决方案.