手眼标定解决方案
上一篇教程介绍了手眼标定需要解决的问题, 本篇教程将描述手眼标定解决方案的背景思想。eye-to-hand和eye-in-hand的核心思想是一样的, 因此我们将先详细描述eye-to-hand的解决方案,然后再说明eye-in-hand与之的区别。
备注
手眼标定并不需要工具或知道其位姿(如果安装了工具), 工具中心点 (TCP) 的值不会影响手眼标定的结果。在本文和以后的教程中,末端执行器是指工具法兰/末端连杆(end-link)。
Eye-to-hand
如何进行eye-to-hand标定?
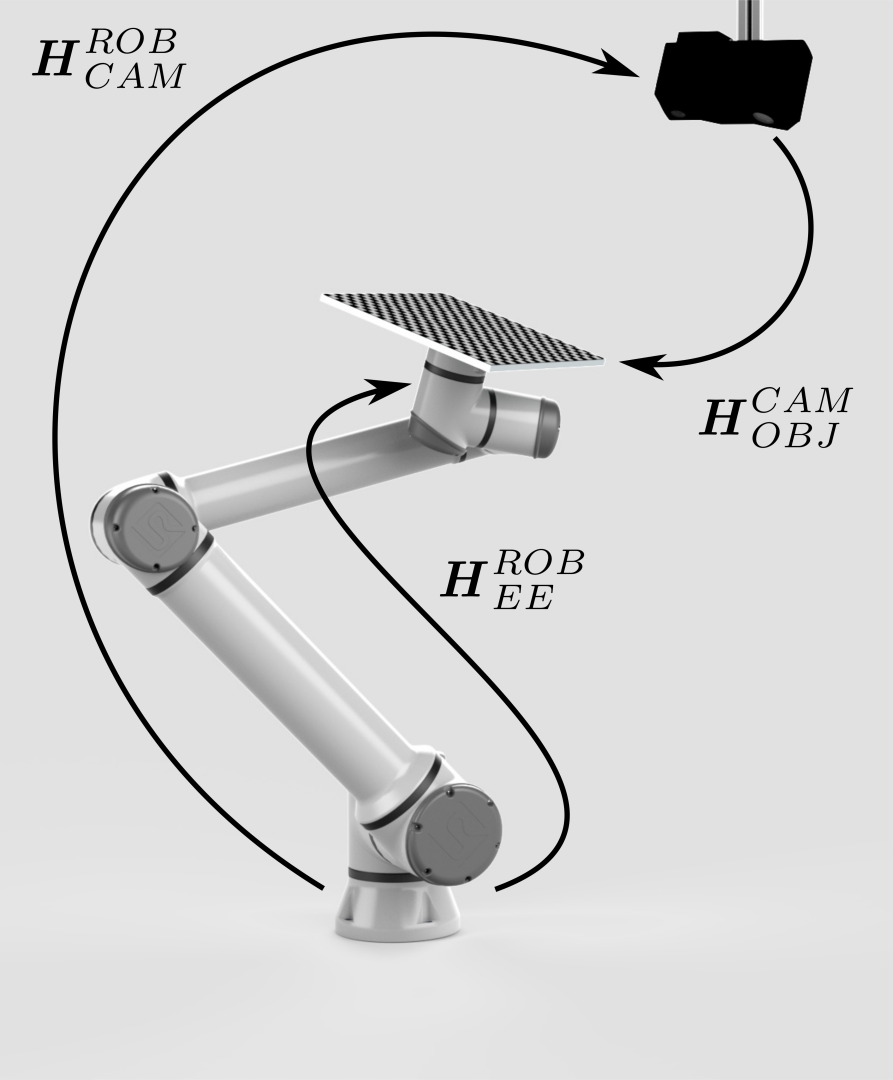
第一步是选择标定对象,例如棋盘格。 后面的教程将介绍 Zivid棋盘格 。 |

|
标定对象具有已知的几何形状。因此,可以从相机图像中识别它。然后估计出它相对于相机的位姿 (\(H^{CAM}_{OBJ}\)) 。 |
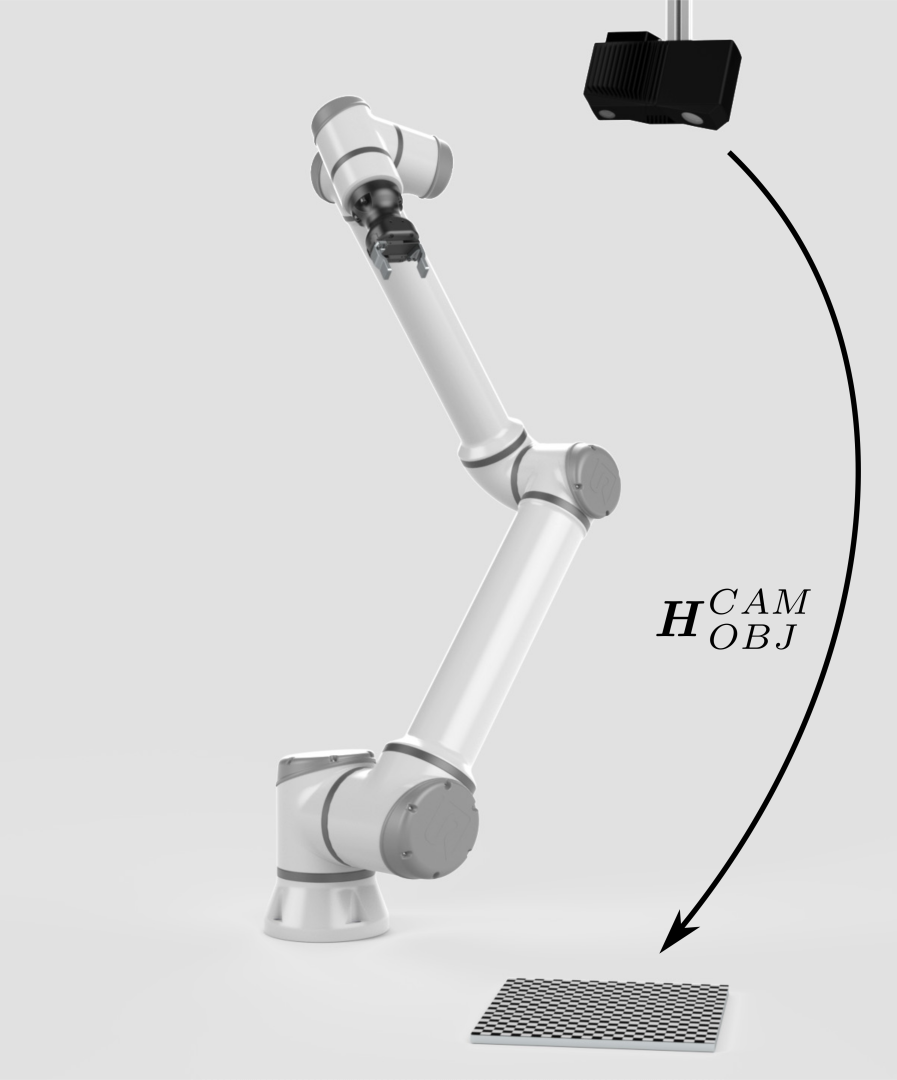
|
要计算相机和机器人之间的相对位姿 (\(H^{ROB}_{CAM}\)),我们需要以某种方式关联位姿。 |
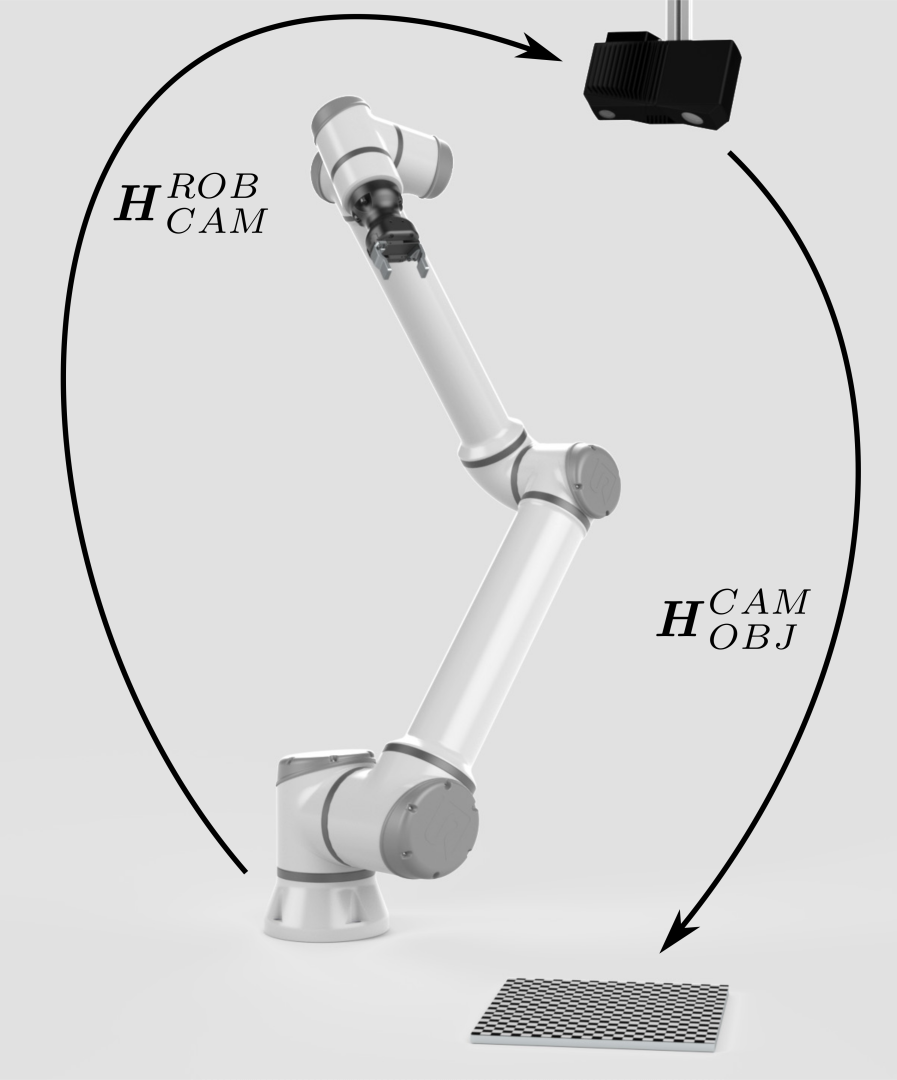
|
末端执行器相对于机器人基座的位姿 (\(H^{ROB}_{EE}\)) 是已知的,由机器人控制器提供。 |
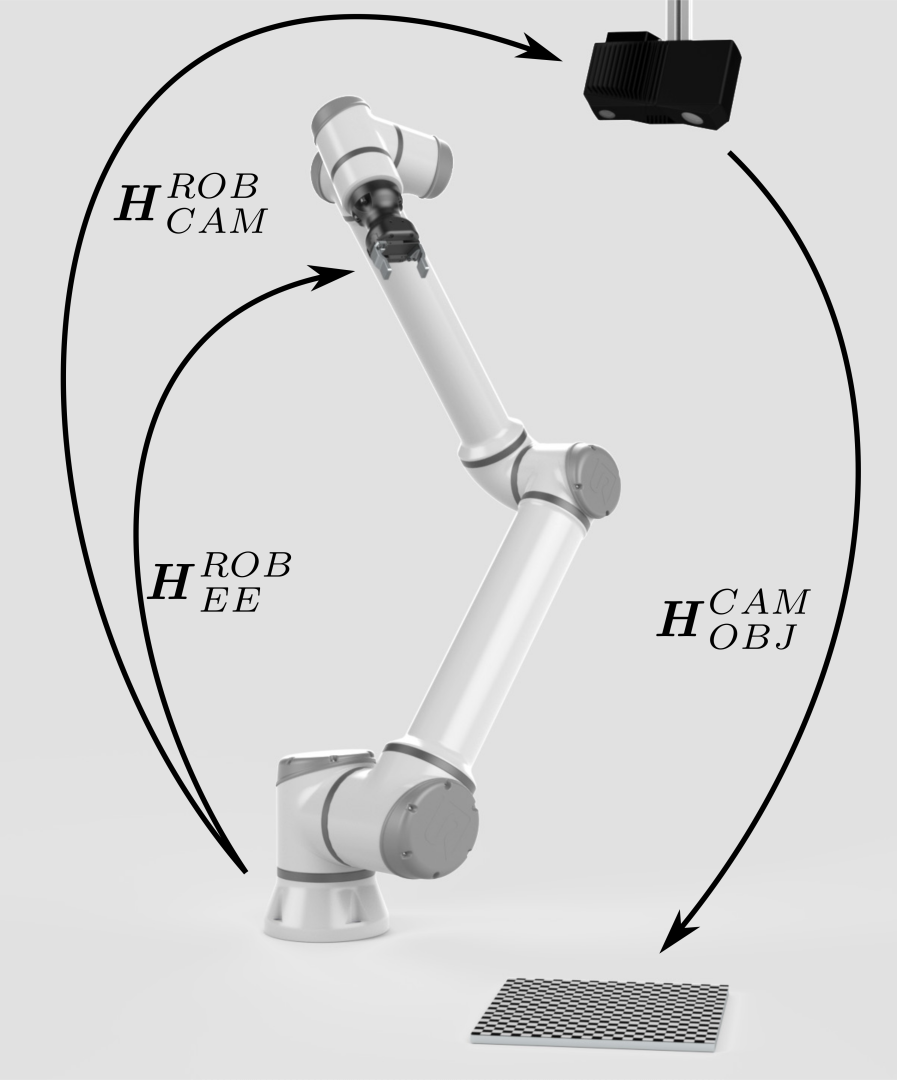
|
右图中缺失的一环是标定对象相对于末端执行器的位姿 (\(H^{EE}_{OBJ}\))。 |
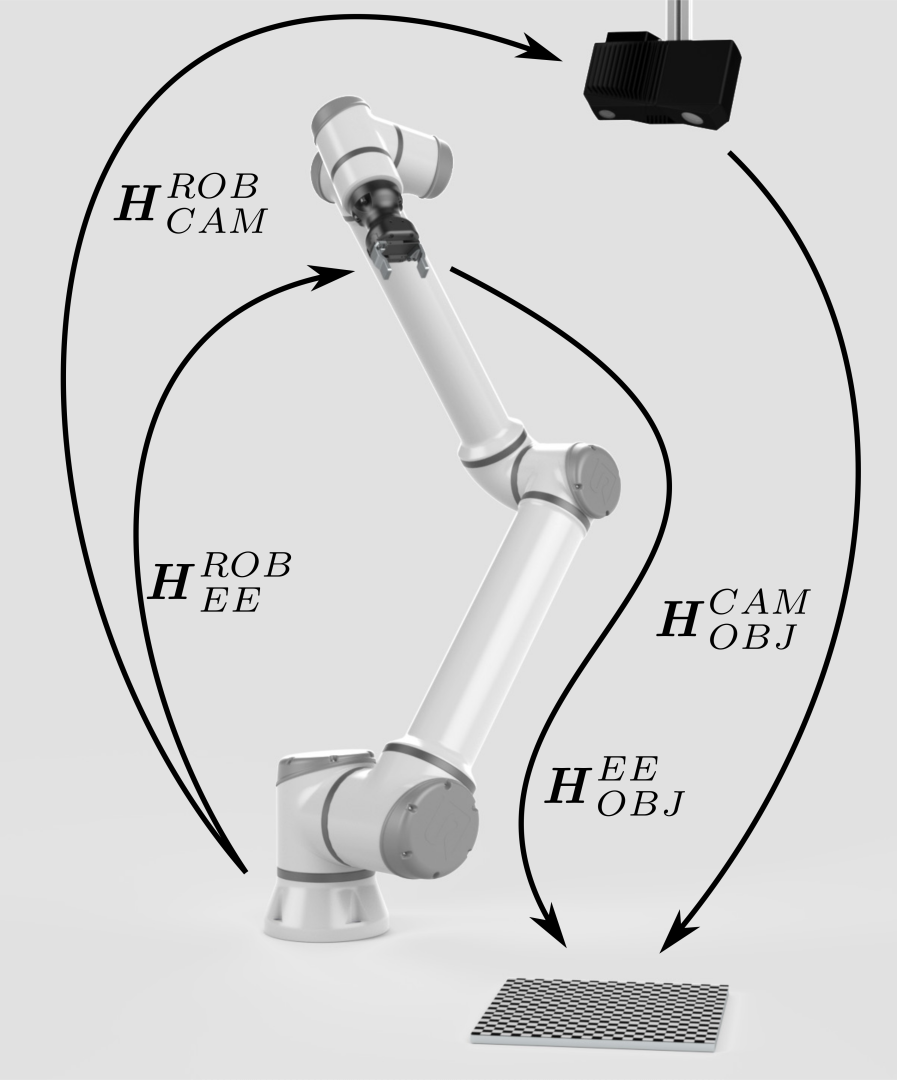
|
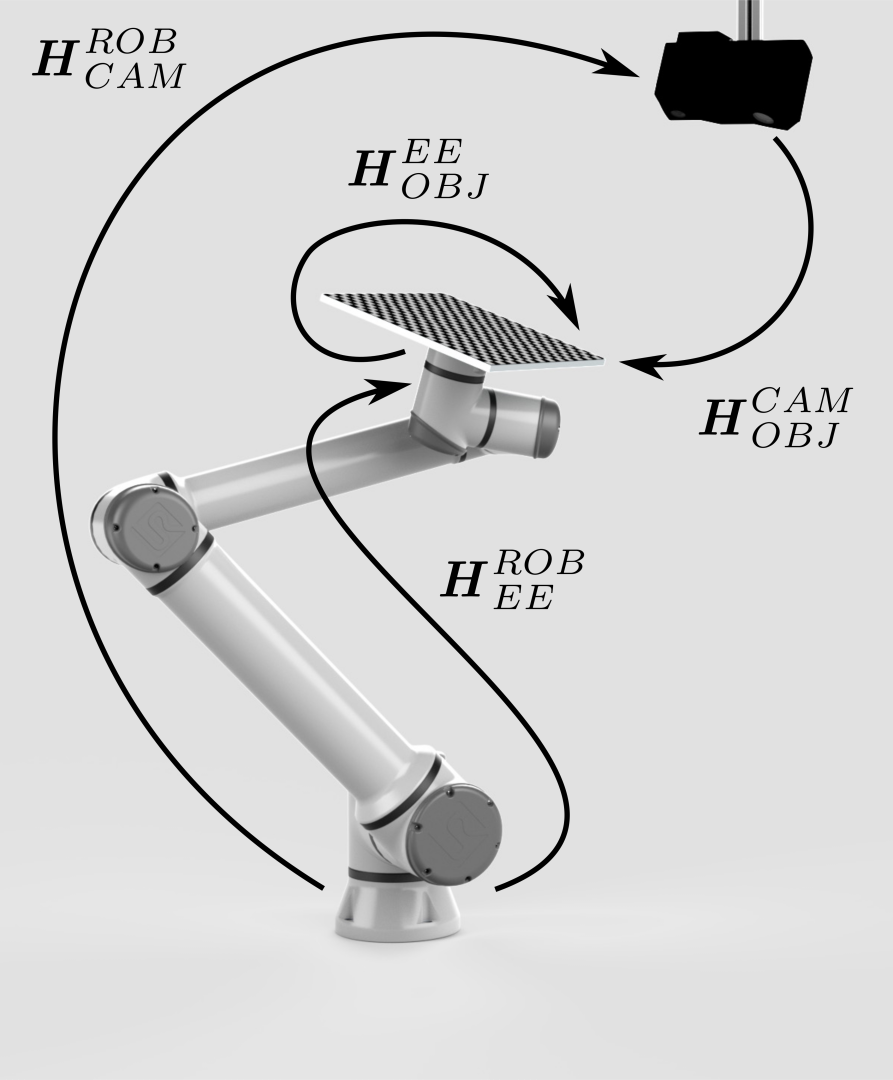
要”摆脱”或者”解决”这个位姿,我们可以将标定对象安装到机器人末端执行器上。 |

|
现在看来我们已经具备了关闭位姿闭环的一切条件,从而计算出相机相对于机器人的位姿 (\(H^{ROB}_{CAM}\))。然而,事情并没有那么简单。 |
|
这是因为我们还没有真正”摆脱”相对姿势 (\(H^{EE}_{OBJ}\))。但是我们已使其保持不变。现在, \(H^{EE}_{OBJ}\) 在机器人运动过程中都不会改变。 这使我们能够将机器人移动到一组不同的位姿。对于每一个位姿, \(H^{ROB}_{CAM}\) 都可以表示为剩余的两个变量的函数,已知位姿:
通过这组方程,可以利用最佳的方式(例如蔡氏方法)来计算所需的位姿 \(H^{ROB}_{CAM}\). |
|
Eye-in-hand
如何进行eye-in-hand标定?
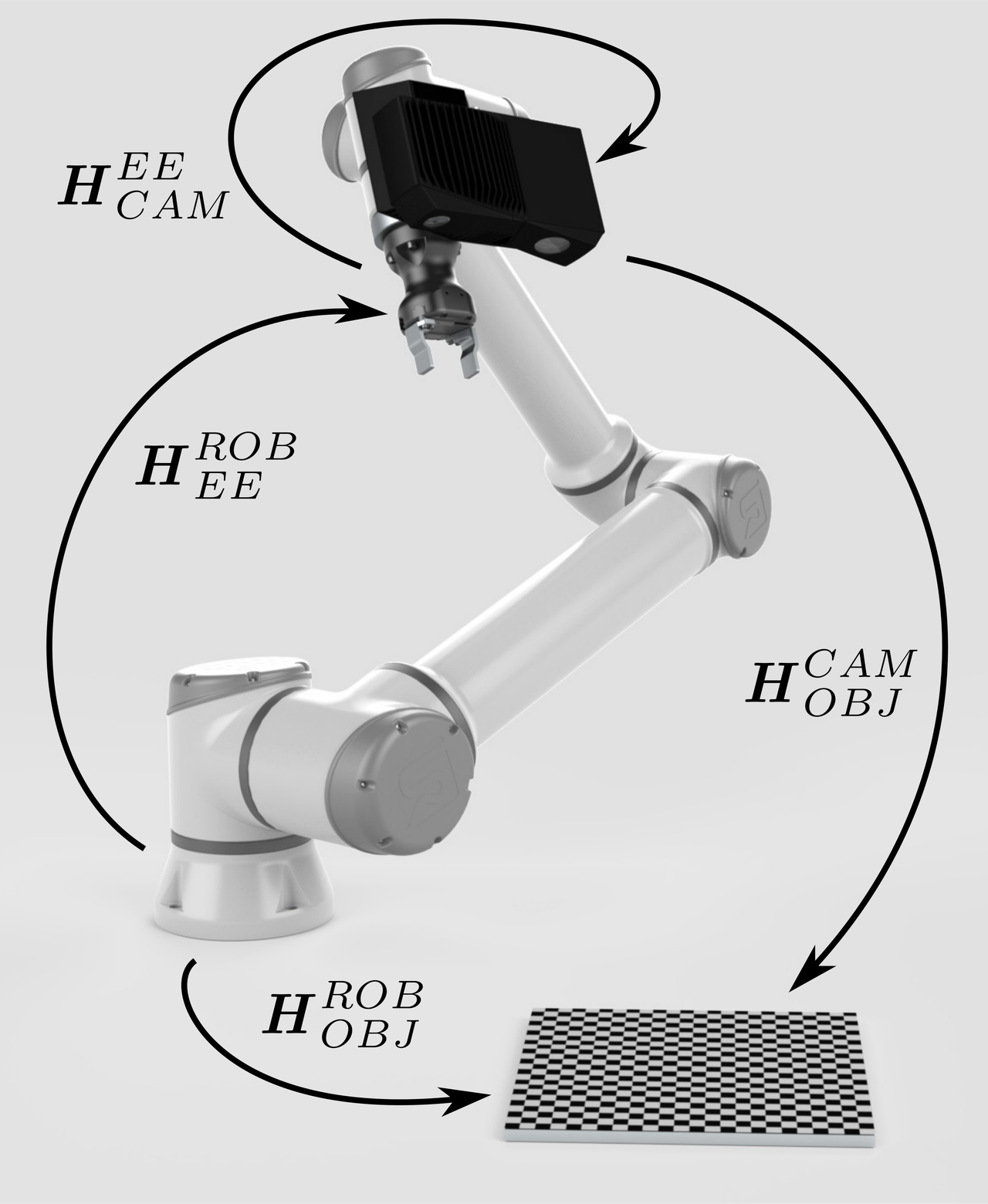
对于eye-in-hand系统,情形非常相似。 在这种情况下,标定对象固定在工作区域内,因此其在机器人运动期间相对于机器人基座的位姿是恒定的。 |

|
这使我们可以将相机相对于末端执行器的位姿 (\(H^{EE}_{CAM}\)) 表示为两个变量的函数,已知姿势:
和eye-to-hand的配置案例一样,这样我们即可解决 \(H^{EE}_{CAM}\)。 |
|
现在我们已经解释了如何解决手眼标定的问题,接下来让我们了解一下 标定对象。