手眼标定的问题
本教程旨在描述手眼标定解决的问题,并介绍手眼标定所需的机器人位姿和坐标系。eye-to-hand系统和eye-in-hand系统的问题是相同的。因此,我们将首先对eye-to-hand配置进行说明,然后我们将描述eye-in-hand配置与之的区别。如果您还不熟悉(机器人)位姿和坐标系,请查看 位置、方向和坐标变换.
Eye-to-hand
机器人如何拾取物体?
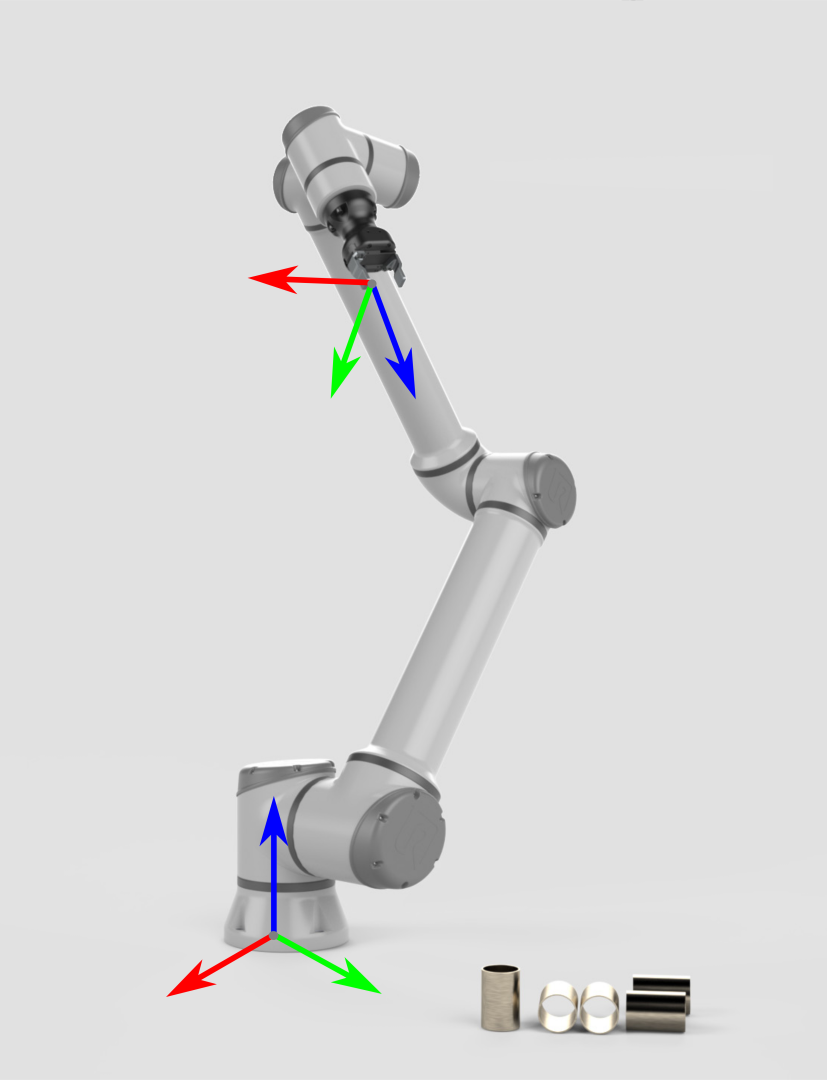
让我们从一个不涉及到相机的机器人开始。它的两个主要坐标系是:
|
|
为了能够拾取物体,机器人控制器需要知道物体相对于机器人基座标系的位姿(位置和方向)。 通过这些信息以及机器人相关的几何知识,即可计算出末端执行器/夹具朝物体移动的关节角度。 |
|
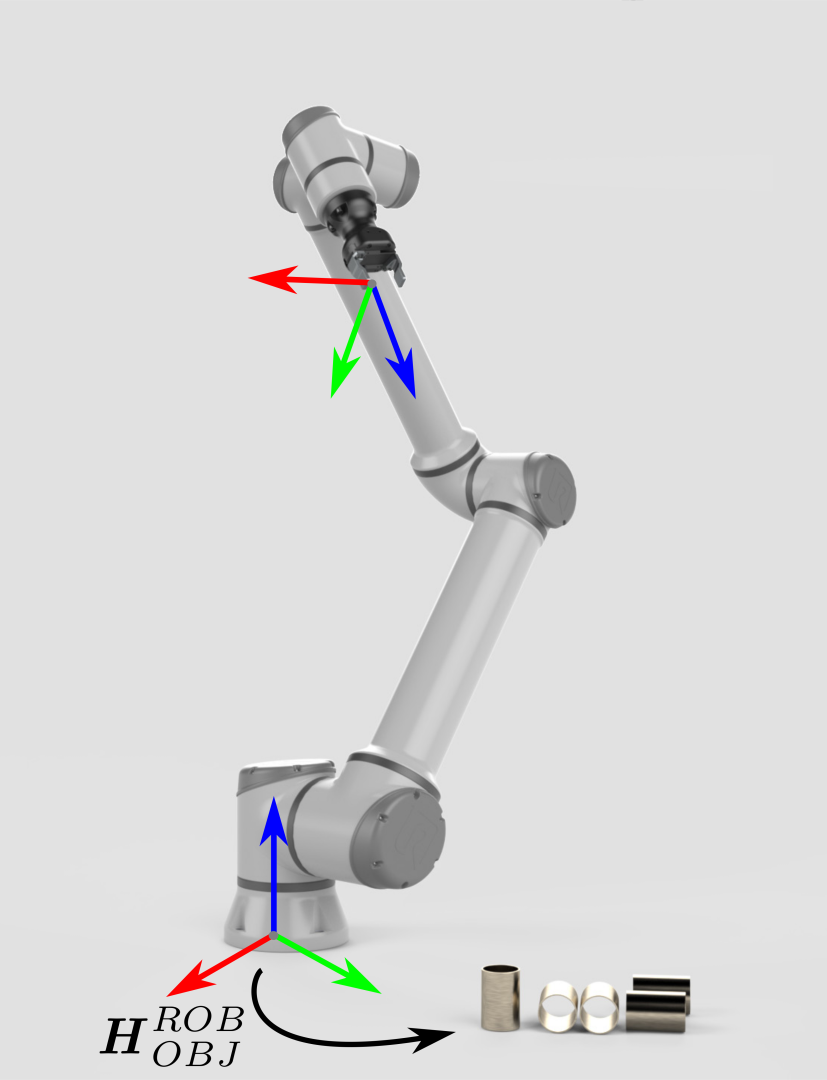
假如物体相对于机器人的位姿是未知的,那么这就是Zivid 3D视觉发挥作用的地方了。 |
|
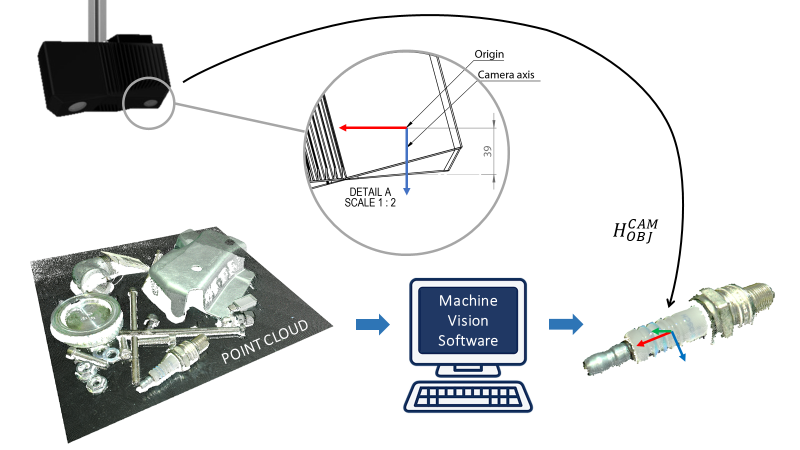
Zivid相机输出的点云是基于相机坐标系的。该坐标系的原点在Zivid成像器镜头(内部2D相机)的中间。机器视觉软件可以在此数据点集合上运行检测和定位算法,确定物体在Zivid相机坐标系中的位姿 (\(H^{CAM}_{OBJ}\))。
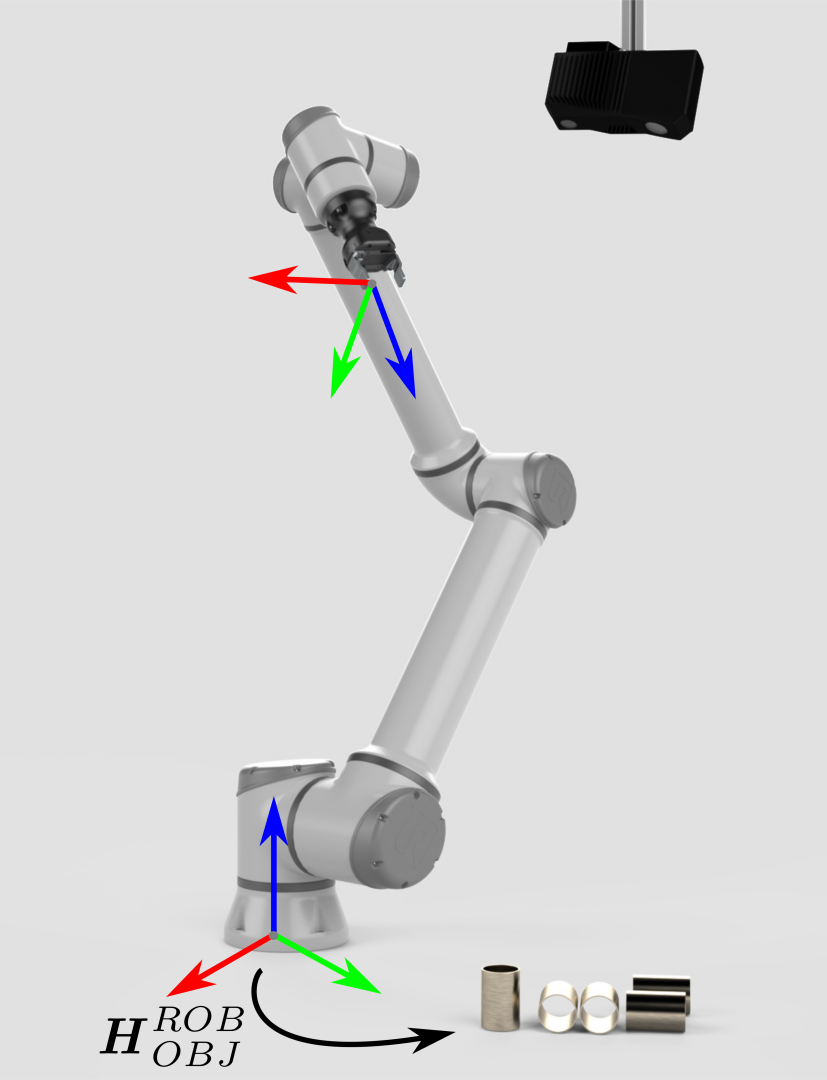
现在,Zivid相机可以在其视野中观测到物体,但其数据仅与自身的坐标系相关联。 为了使机器人能够拾取物体,必须将物体的坐标从相机坐标系转换到机器人基坐标系。 |
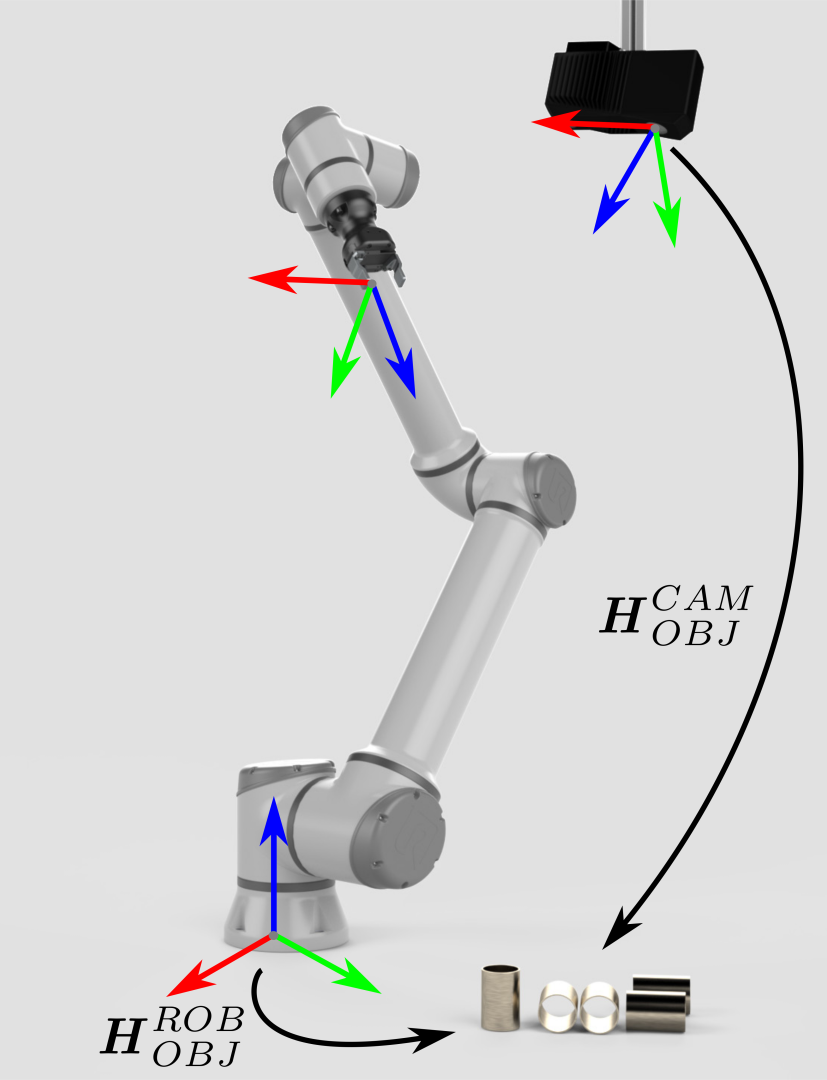
|
Zivid相机输出的点云是基于相机坐标系的。该坐标系的原点在Zivid成像器镜头(内部2D相机)的中间。机器视觉软件可以在此数据点集合上运行检测和定位算法,确定物体在Zivid相机坐标系中的位姿 (\(H^{CAM}_{OBJ}\))。 位姿关联完成后,就可以通过关联圈中的任意一种位姿数据计算出另一姿势。在这里,物体相对于机器人的位姿,是通过将相机相对于机器人的位姿与物体相对于相机的位姿通过后乘法得到的:
\[H^{ROB}_{OBJ}=H^{ROB}_{CAM} \cdot H^{CAM}_{OBJ}\]
|
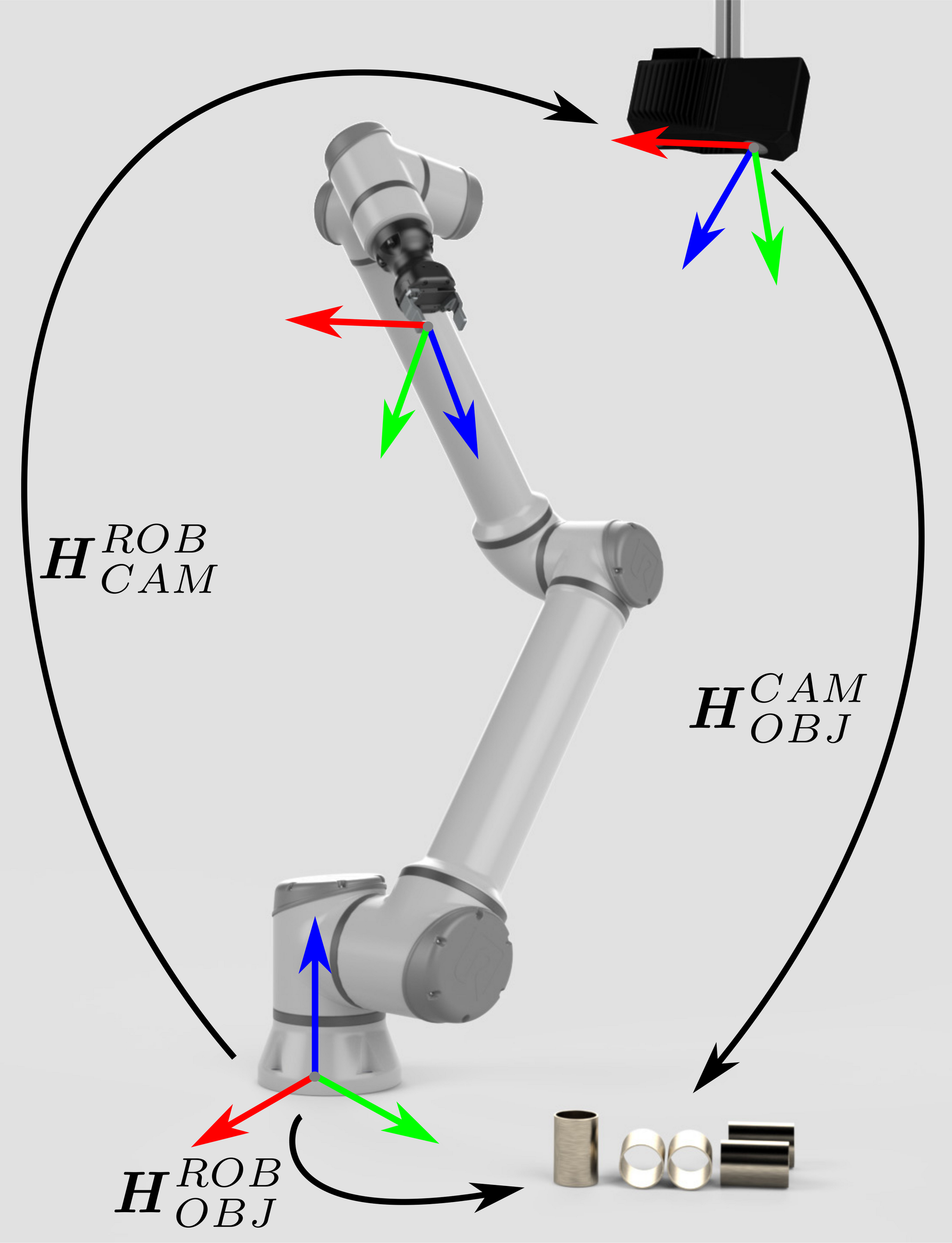
|
Eye-in-hand
机器人如何拾取物体?
Eye-in-hand的目标是一样的。 为了使机器人能够拾取物体,需要将物体的位姿从相机的坐标系转换到机器人的基坐标系。 |
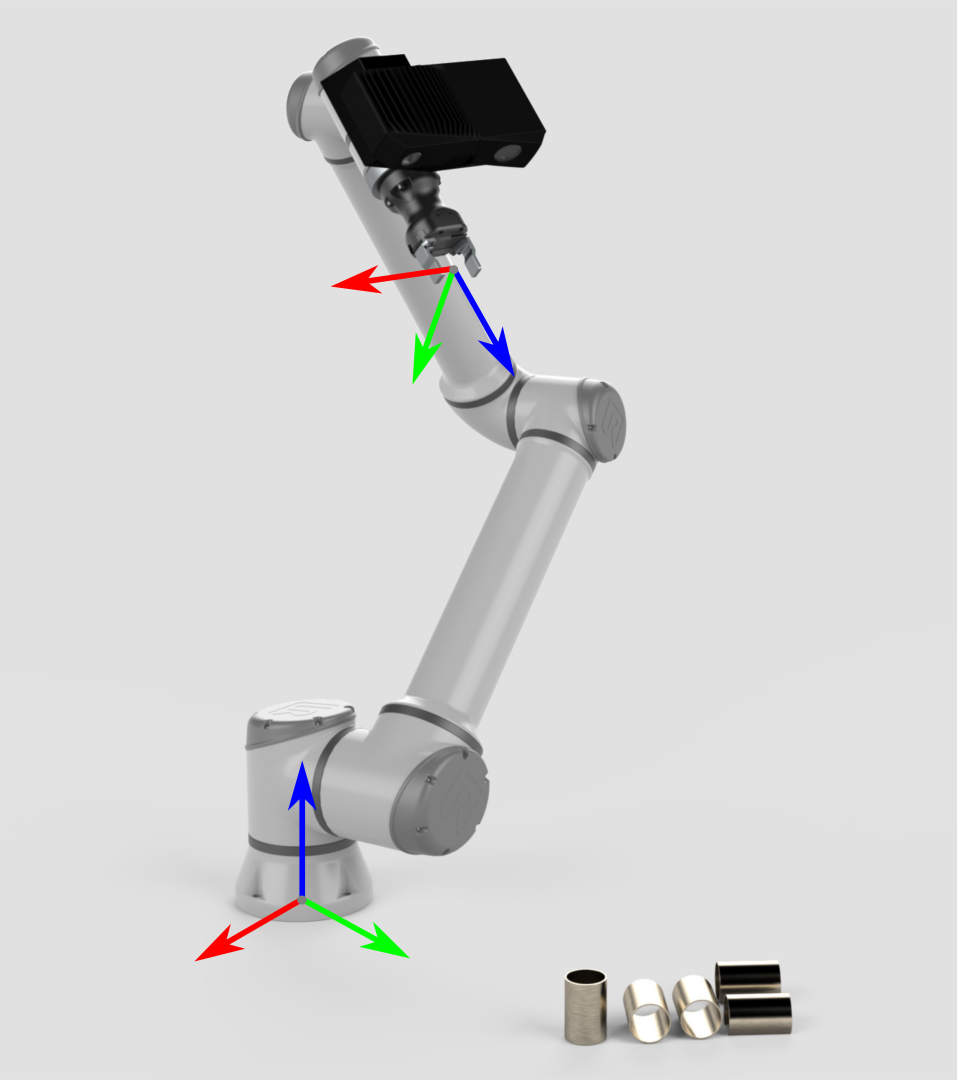
|
在这种情况下,坐标转换是间接完成的:
\[H^{ROB}_{OBJ}=H^{ROB}_{EE} \cdot H^{EE}_{CAM} \cdot H^{CAM}_{OBJ}\]
末端执行器相对于机器人基座的位姿 (\(H^{ROB}_{EE}\)) 是已知的,由机器人控制器提供。相机相对于末端执行器的位姿 (\(H^{EE}_{CAM}\)),在这种情况下是一个常量,是根据手眼标定估计的。 |
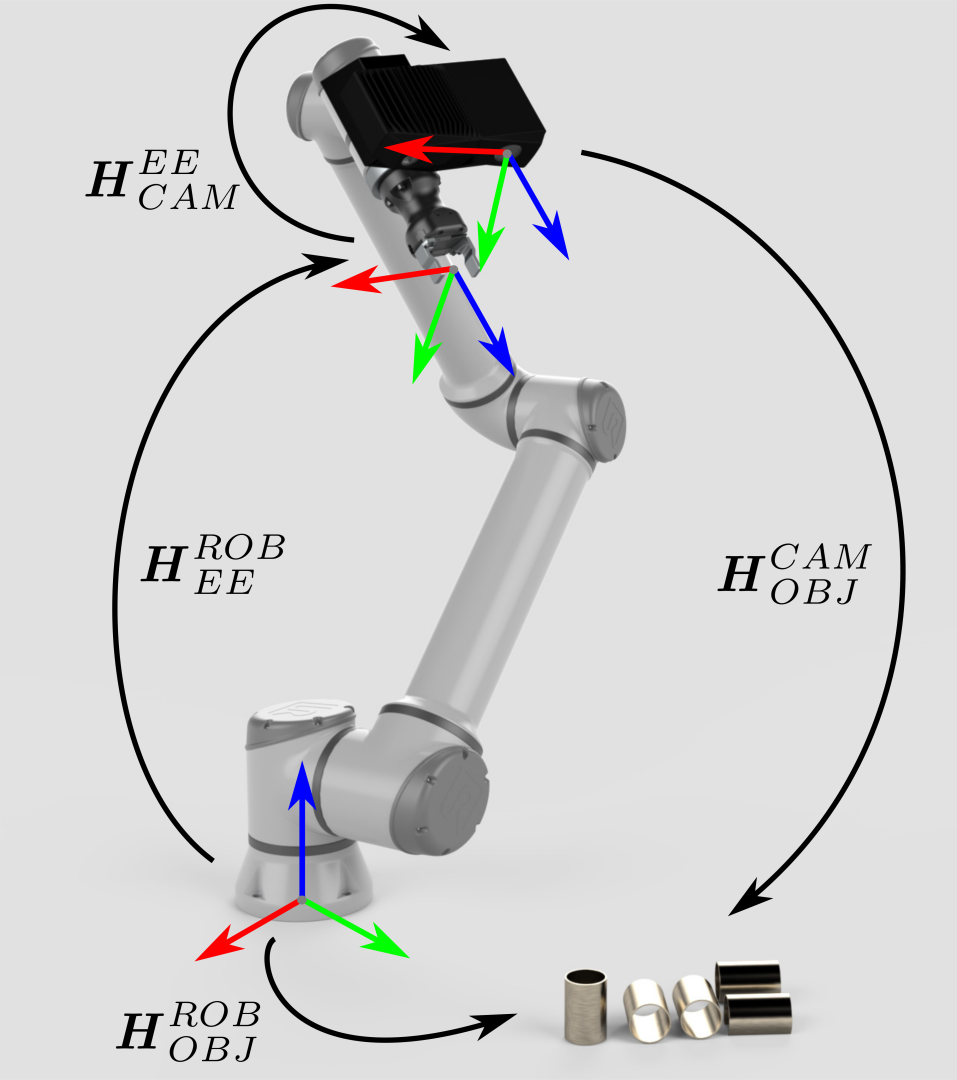
|
现在我们已经定义了手眼标定的问题,让我们看看 手眼标定解决方案.